2023. 11. 16. 19:41ㆍBACKEND
주로 React.js/Next.js 와 node.js 환경에서만 개발해본 상태에서
자바를 처음 배웠을 당시 느꼈던 부분이나 독특했던 부분, 기억해야 할 만한 부분에 대해 정리하였다.
JAVA의 개요
썬 마이크로시스템즈에서 1995년에 개발한 객체 지향 프로그래밍 언어. 창시자는 제임스 고슬링이다. 2010년에 썬이 오라클에 인수되어서 현재 Java의 저작권자는 오라클이며, 2019년 1월부터 유료화되었다. 단, Java EE는 이클립스 재단의 소유이다.
JAVA의 버전
자바는 버전이 다양하다, 처음 자바를 접했을때 1.8과 8,12 등등 여러가지의 버전과 EE SE 등등 여러가지의 버전으로 혼란스러웠다.
Java SE = 자바 표준안, 문법적 구성과 규칙
Java JDK = 자바개발에 필요한 도구들이 내장되어있고 구성요소를 포함하는 kit이다
Java JRE = 자바로 만든 프로그램을 실행하기 위한 라이브러리와 각종 파일들을 가지고 있다 (JDK 안에 포함되어있음)
Java JVM = 자바가 실제 구동되는 환경, 하드웨어나 운영체에 상관없이 동작할 수 있도록 하는것이 자바의 핵심적인 철학인데
그게 가능하도록 하는 것이 Java Viltual Muchine 이다.
Java SE = 가장 기본적이며 일반적으로 사용하는 자바버전
Java EE = 기업용 시장에서 사용하는 자바 개발환경
Java Me = 모바일 개발을 위해 사용하는 자바버전
JAVA 버젼별 성능비교

- Java5 -> Java6 : 18% 성능향상 - Java6 -> Java7 : 46% 성능향상
- 낮을 수록 좋은 성능

- Java6 -> Java7 : 평균 16% 성능향상
- Java7 -> Java8 : 평균 1% 성능향상
오픈소스나 소스 라이브러리 release 시 GA, SNAPSHOT의 의미
스프링 시큐리티와 관련된 내용들을 읽다보면 GA 및 SNAPSHOT이라는 태그가 있는 것들을 보게된다, 자신에게 필요한 스프링 시큐리티 소스에 맞게 버전을 선택할 필요가 있다.
- GA (General Availability) - 테스트가 완료된 정식 릴리즈 버전으로 안정적으로 운영되어야 하는 프로젝트에서 사용. 대부분 GA 버전을 가져다 사용하면 된다.
- RC (Release Candidate) - 베타 버전이다. 정식 릴리즈 버전은 아니므로 기능은 픽스되었으나, 안정적 동작은 보장할 수없다.
- M (Milestone) - 테스트 버전이다. 아직 기능이 픽스되지 않아 구현될때마다 테스트 버전이 릴리즈 될 수 있다.
- SNAPSHOT - 스냅샷이 붙으면 아직 개발단계라는 의미이며, 일종의 백업시점인 것이다.
JAVA의 장점
1. 기기의 호환성
- 장점으로는, 해당 운영체제에 Java Virtual Machine(JVM)을 설치하면 Java로 만든 프로그램은 어떤 컴퓨터에서도 완벽히 똑같이 동작한다. 가상머신이 각각의 운영체제에 맞춰서 결과적으로 완벽히 똑같이 돌아갈 수 있도록 제작되는 덕. 가상머신 없는 운영체제라면 아예 Java 프로그램을 사용하지 못하겠지만, 썬 마이크로시스템즈는 주요 OS용의 가상 머신을 발표하고 있고, IBM, 휴렛팩커드 등의 회사는 직접 자사 운영체제용 JDK/JVM을 제작하여 발표하며, 이들과 상관없이 독립적으로 특화된 성능향상 기능을 가진 JVM을 만들어서 발표하는 회사도 존재한다.
2. 안정성
- 다른 언어에 비해 높은 안정성을 꼽고 있다. 우선 C나 C++에 안정성 문제가 제기되는 포인터 연산자 및 메모리 직접접근 함수들을 지원하지 않는다. 여기에 C++과는 다르게 다중 상속을 허용하지 않는다. 이는 객체지향의 특성 중 하나인 '상속'의 자유도를 확 떨어트리는 것이기에 언뜻 보기에는 객체지향적 관점에 위배되는 것처럼 보일 수 있으나, 반대로 오히려 이게 더 객체지향적이라고 볼 수도 있다. 객체지향의 목적 자체가 재사용을 통한 생산성의 향상과 관리 상의 이점인데, 다중 상속은 잘못 사용할 시 극도로 복잡하게 꼬인 프로그램을 만들 위험성을 갖고 있다. 물론 코드 관리의 측면에서도 다중상속에 의해 발생하는 문제는 좋지 않다. 수준 높은 프로그래머라면 이 문제도 잘 해결할 수 있지만, Java는 아예 미연에 방지하기 위해 다중상속을 언어 스펙에서 제거하는 방법을 택했다.
3. 가독성
- 고급 프로그래밍 언어가 만들어진 첫째 목적은 '좀 더 인간 친화적인' 코드의 작성을 돕는 데 있다. 기계어가 어셈블리어로 진화하고 그것이 C언어로 진화한 배경에는 '사람이 더 쉽게 읽고 이해할 수 있는 코드'가 있다. Java는 동시기에 발표된 다른 언어에 비해 코드가 명료하고 가독성이 뛰어났다. C++은 어려운 문법으로 인해 코드가 이리저리 꼬이는 경우가 많고, 특히 연산자 오버로딩과 템플릿 기반의 일반화 프로그래밍(Generic Programming) 개념이 코드 난독화에 결정타를 날렸는데 Java는 연산자 오버로딩을 배제하고 오로지 메소드를 통해서만 객체의 조작을 허용함으로써 코드의 일관성을 지켜냈다.
JAVA의 단점
- 속도 문제
- 여기서 잠시 유의할 점은, 느리다는 내용은 대부분 C/C++, Pascal, Fortran 같은 네이티브 바이너리 코드를 만드는 언어와 비교했을 때의 이야기이다. Java가 C/C++보다 2~3배 느리다고 하지만 다른 고수준 언어들에 비해서는 그리 떨어지지 않는다. 특히 인터프리터/스크립트 언어는 구조적으로 Java에 비해서도 훨씬 느리다는 것을 기억하자. 예를 들어 요즘 인기있는 Python은 C보다 수십 배 느리다. 그나마 빠르다고 하는 JavaScript도 Java에 비해서 2배 정도 느리다.
- 불편한 예외 처리
- Java 역시 try~catch문으로 대표되는 예외 처리를 할 수 있다. 대부분의 언어에서 차용하고 있는 좋은 기능이지만... 유독 Java는 다른 언어와는 달리 프로그래머의 검사가 필요한 예외(Exception을 직접 상속하는 예외 클래스)가 등장한다면 무조건 프로그래머가 선언을 해줘야 한다. 그렇지 않으면 컴파일조차 거부한다.
JAVA의 기본 데이터형
자바스크립트 에는 데이터형의 개념이 약하다. 데이터 형이 없는건 아니지만 변수를 선언하거나 값을 가져와 사용할때 자동형 변환때문에 크게 신경쓸 일이 없다.
- 정수형
- byte, short, int ,long (아무것도 쓰지않으면 int 로 잡는다)
- 소수점에 없는 정수
- 10진수, 16진수, 8진수, 2진수
- 기본적으로 사용하는기준 : int
- 실수형
- float, double (아무것도 쓰지않으면 double 로잡는다)
- 소수점이 있는 실수, 지수
- 기본본적으로 사용하는 기준 : double
- 논리형
- boolean
- true / false (논리형 리터럴) [리터널=값 ]
- 문자형
- char
- 문자 한자
- 유니코드 / escape 코드
- 'a' (단일 따음표 안에 있어야한다)
- 문자열
- String (혼자만 대문자를 쓴다)
- 문자열 -"string"
기억하기
1. byte -> short -> int -> long -> float -> double 순으로 형변환이 가능하지만 역으로는 불가능하다, 자신보다 더 큰 수를 표현할 수 없기 때문이다.
2. 기본적으로 정수를 표현할때 상수의 데이터형은 int로 설정되어 있다. 하지만 byte나 short를 사용할때 자동으로 상수의 데이터형을 변환해준다.
하지만 long을 사용하고싶은 경우 상수의 데이터형을 long을 사용한다는 의미의 L을 붙여주어야한다. 예) long a = 100L; 과 같이 상수값 뒤에 long상수타입이라는 것을 표시하시 위해 L을 붙여주어야 한다.
실수를 사용할때 에도 기본적으로 double타입으로 상수의 데이터타입을 설정하기 대문에 float형을 쓰고싶다면 F를 붙여야 한다. 예) float a = 2.5F;
참고로 char변수를 int로 변형할 수 있지만 int가 char 변수가 될수는 없다. 결국 문자열도 숫자로 인식해 표현하기 때문이다.
접근제어자(Access Modifier) 와 패키지(package)
자바에서는 디렉토리대신 패키지라는 개념을 사용한다. 윈도우를 사용할때 폴더를 만들어 파일을 관리하는것 처럼 자바에서 파일을 관리할때 package를 이용해 관리한다. 디렉토리=패키지 라고 생각해도 무방할 것 같다. 그리고 자바의 클래스앞에는 접근제어자 라고하는 것들이 붙게되고 접근제어자에 따라 다른 패키지에서 사용할 수 있는지의 유무가 변하게된다.
클래스앞에 public, protected, default, private 와 같은 키워드를 붙여 접근제어자를 정할 수 있다.

- public : 다 사용이 가능하다
- protected : 다른 패키지에 있는 경우 클래스를 상속하면 사용이 가능하다
- default : 같은 패키지만 사용 가능하며 상속하더라도 사용 할 수 없다, (클래스 앞에 아무것도 안붙이면 자동으로 default가 됨)
- private : 자기가 속한 클래스 내부에서만 사용할 수 있다.
글쓴이가 느끼기엔 평소 public과 private만 사용했는데 다른 프레임워크나 모듈을 사용하다보면 protected나 default로 작성된 클래스들이 있어 개념을 이해하는것도 필요한것 같다.
Interface
interface i{
public void z();
}
class a implements i{
public void z(){}
}
클래스대신 interface라는 키워드를 붙여 정의하면 implements를 통해 구현 한다. 구현된 것은 아무 것도 없는 밑그림만 있는 기본 설계도이며 인터페이스는 표준, 약속, 규칙 이다
예를들어 프론트개발자와 백엔드 개발자가 개발을할때 실제 api 혹은 데이터가 없는경우 프론트에서 dummy 데이터와 redux의 대략적인 모양새를 만들어 놓는데 이렇게 예상을 통해 작업을 구현하는 것처럼 자바에서는 interface를 통해 개발자들끼리 class와 method의 타입, 리턴값 등등 중요한 내용을 미리 정해놓을 수 있다. interface 에서 미리 기본적인 사항들이 정해져있는 상태에서 implements해서 클래스를 사용하면 추후에 여러 분야의 개발자들이 작업물을 하나로 합칠때 구조나 타입 등의 차이로 인해 문제가 생길것을 방지하기 위함 이다. interface 내에 써있는 method는 public으로 만들어야 한다.
Abstract
abstract class Animal {
String animal_name;
Animal(String name) {
animal_name = name;
}
public abstract void cry();
public abstract void behavior();
}
class Tiger extends Animal {
public Tiger(String name) {
super(name);
}
@Override
public void cry() {
// TODO Auto-generated method stub
System.out.println("어흥");
}
@Override
public void behavior() {
// TODO Auto-generated method stub
System.out.println("우측으로 빠르게 움직인다.");
}
}
class Dog extends Animal {
public Dog(String name) {
super(name);
}
@Override
public void cry() {
// TODO Auto-generated method stub
System.out.println("멍멍");
}
@Override
public void behavior() {
// TODO Auto-generated method stub
System.out.println("왼쪽으로 느리게 달린다");
}
}
어떨때 써야할까?
클래스는 일반 클래스와 추상 클래스로 나뉘는데(아마 구체적으로 정의하면 더 많을 것이다.) 추상 클래스는 클래스 내 '추상 메소드'가 하나 이상 포함되거나 abstract로 정의된 경우이고, 인터페이스는 모든 메소드가 추상 메소드인 경우다 두 키워드가 다소 비슷한 개념을 가지기도 하는데 abstract는 class와 별반 다르지않다. 그저 상속을 강제할 뿐이다. abstract 메소드 안에 로직이 담길수 있다. 하지만 interface는 오롯이 뼈대이자 클래스의 명세만을 위해 쓰이는 것이기 때문에 별도의 로직을 가져서는 안되고 껍데기 즉, 만들어질 객체의 메소드명, 리턴타입, 접근제어자, 매개변수의 갯수와 타입 같은것만을 명시해야 한다. (여러 개발자의 개발과정에서 기초적인 found가 중구난방이 되는것을 막기위해)
결론적으로 interface는 명세서의 개념이며 abstract는 상속해서 써라! 를 강제하는것이다. 상속을했으니 기능을 확장하는 것이 가능해진다.
비슷해 보이는데 자바를 만든 사람들은 왜 두개를 따로 설계한 만든것일까?
이는 자바가 다중 상속을 지원하지 않기 때문이다. 다중 상속은 아래와 같이 여러 개의 슈퍼클래스를 두는 것을 의미한다.
class MyVehicle extends car, plane {
@Override
public void goTo(){
super.drive();
}
}
만약 car, plane 클래스 모두 drive()라는 메소드를 가지고 있다면, 어떤 메소드가 실행될까? 다중 상속의 모호함이다. 1편에서 자바의 특징에대해 이야기할때 자바는 c++과 다르게 다중상속을 허용하지않고 이런부분이 자바의 안정성을 높인다고 언급했다.
하지만 interface에서는 여러개의 인터페이스를 implements(구현) 하는것이 가능하다.
class car implements vehicle,engine
@Override
public void drive(){
@doSomething
}
}
얼핏보면 여러개를 상속하는것 처럼 보이지만 상속과 다형성이라는 키워드로 구분하면 될것같다.
제네릭 (Generic)
자바 5 버전부터 제네릭이 추가되었다.
일반적으로 생각하는 데이터 타입은 int, char, double...같은 것들이 있다. 그런데 제네릭은 데이터 타입을 명시하지않고 선언했다가 인스턴스를 만들때 지정해주는것이다. 관용상 T라고 적어준다 제네릭 구현 방법은 아래와 같이 사용할 수 있다.
public class 클래스명<T>{ ... }
public interface 인터페이스명<T>{ ... }
그렇다면 왜써야될까?
1. 타입변환을 제거하여 성능을 높여준다.
Box.java
public class Box {
private Object object;
public Object get(){return object;}
public void set(Object object){this.object = object;}
}
Main.java
public class Main {
public static void main(String[] args) {
Box box = new Box();
box.set("제네릭");
String str = box.get();//(String)box.get(); 캐스팅필요
System.out.println(str);
}
}
위 코드에서 에러가 발생할 것이다. Object를 String으로 변환해야 할 필요가 있기떄무니다.
매번 데이터타입을 강제로 캐스팅을 한다면 성능저하가 발생되기 때문에 인스턴스화시 타입을 지정해줘서 불필요한 강제타입변환을 막을 수 있다.
Box.java
public class Box<t> {
private T t;
public T get(){return t;}
public void set(T t){this.t = t;}
}
Main.java
public class Main {
public static void main(String[] args) {
Box<string> box = new Box<string>();
box.set("제네릭");
String str = box.get();
System.out.println(str);
}
}
인스턴스화 할때 Box<String> box = new Box<String>(); 부분이 String으로 타입을 지정해주었다.
2. 코드의 재사용
제네릭을 사용하지 않는다면, box.set(데이터타입); 처럼 필요한 데이터타입에 맞는 새로운 클래스 또는 메서드를 작성해야한다. 제네릭을 통해 인스터스를 할때 타입을 지정하면 클래스 내부적으로 T 제네릭타입은 인스턴스 할때 지정한 타입으로 자동 재구성된다.
3. 엄격한 타입체크
package org.opentutorials.javatutorials.generic;
class StudentInfo
{
public int grade;
StudentInfo(int grade){ this.grade = grade; }
}
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person<t>{
public T info;
Person(T info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
Person<employeeinfo> p1 = new Person<employeeinfo>(new EmployeeInfo(1));
EmployeeInfo ei1 = p1.info;
System.out.println(ei1.rank); // 성공
Person<string> p2 = new Person<string>("부장");
String ei2 = p2.info;
System.out.println(ei2.rank); // 컴파일 실패
}
}
</employeeinfo></employeeinfo>
기존에 우리가 object로 작성한 코드는 모든 데이터 타입을 받아주기 위한 취지로 object를 썼지만, 그렇게 하면 개발자가 우리가 의도한 데이터타입을 사용하지 않고 위 코드처럼 우리가 의도하는 인스턴스 객체타입이 들어가야할 자리에 "부장" 이라는 String 타입이 들어가는 것을 막을 수 없다. 하지만 Generic(제네릭)을 사용하면 위와 같은 잠재성이 있는 에러를 런타임 사전에 에러체크 할 수 있다.
Collections Framework
자바스크립테 에서는 배열을 사용할때 그냥 const arr = [] 이런형태로 배열을 만들고 필요할때마다 push를통해 값을 넣어주면된다. 그런데 자바에서는 배열을 사용할때 최초의 크기를 지정해주어야 하고 이 크기가 변경될 수 없다. 이러한 불편함을 극복하기위해 프리엠워크를 사용하는것이고, Collections Framework중 하나로 ArrayLst가 있는것이다.
Collections Framework라는 것은 다른 말로는 컨테이너라고도 부른다. 즉 값을 담는 그릇이라는 의미이다. 그런데 그 값의 성격에 따라서 컨테이너의 성격이 조금씩 달라진다. 자바에서는 다양한 상황에서 사용할 수 있는 다양한 컨테이너를 제공하는데 이것을 컬렉션즈 프래임워크라고 부른다.
ArrayLst
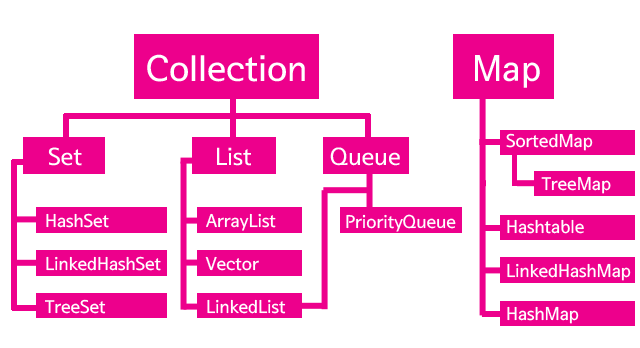
ArrayList는 Collection-List에 속해있다. ArrayList는 LIst라는 성격으로 분류되고 있는 것이다. List는 인터페이스이다. 그리고 List 하위의 클래스들은 모두 List 인터페이스를 구현하기 때문에 모두 같은 API를 가지고 있다. 클래스의 취지에 따라서 구현방법과 동작방법은 다르지만 공통의 조작방법을 가지고 있는 것이다. 익숙한 ArrayList를 바탕으로 나머지 컬렉션들의 성격을 파악해보자.
public class ArrayListDemo {
public static void main(String[] args) {
String[] arrayObj = new String[2];
arrayObj[0] = "one";
arrayObj[1] = "two";
// arrayObj[2] = "three"; 오류가 발생한다.
for(int i=0; i<arrayObj.length; i++){
System.out.println(arrayObj[i]);
}
ArrayList al = new ArrayList();
al.add("one");
al.add("two");
al.add("three");
for(int i=0; i<al.size(); i++){
System.out.println(al.get(i));
}
}
}
위에 코드는 세번째 값을 넣으려 할때 에러가 발생한다. arrayObj를 인스턴스할때 2개의 크기를 가지도록 만들었기 때문이다. 자바스크립트라면 배열을 만들고 나서 배열에 10개를 넣든, 100개를 넣든 상관이 없다.
ArrayList al = new ArrayList();
al.add("one");
al.add("two");
al.add("three");
하지만 위에 코드처럼 ArrayList를 사용하면 크기를 지정하지 않기때문에 필요한 갯수만큼 배열의 크기도 늘어난다.
기억해야할 부분은 ArrayList는 프레임워크이기 때문에 java에서의 순수 배열을 사용할때와 사용법이 조금 다르다는 점이다.
List, Map, Set 의 차이점
- List는 중복을 허용한다. 배열과 거의 유사하다고 생각하면된다.
- Set은 중복을 허용하지않는다. 이미 컬렉션에 1이라는 값이 있는데 다시1을 넣으려고 한다면 에러가 발생하지는 않지만 값은 들어가지않게된다.
- Map 컬렉션은 key와 value의 쌍으로 값을 저장하는 컬렉션이다 객체형태로 저장된다고 보면 되겠다. put(key: value)형태로 값을추가하고 getKey 혹은 getValue로 가져온다.
List의 사용법
생성하기
ArrayList<Integer> numbers = new ArrayList<>();
추가하기
numbers.add(10);
numbers.add(20);
numbers.add(30);
numbers.add(40);
삭제하기
numbers.remove(2);
가져오기
numbers.get(2);
반복하기
Iterator it<Integer> = numbers.iterator();
ArrayList를 탐색할 때는 Iterator를 사용한다. Iterator는 객체지향 프로그래밍에서 주로 사용하는 반복 기법입니다. Iterator를 쓰려면 우선 Iterator 객체를 만들어야 한다.
while(it.hasNext()){
int value = it.next();
if(value == 30){
it.remove();
}
}
it.next() 메소드는 호출될 때마다 엘리먼트를 순서대로 리턴한다. 만약 더 이상 순회할 엘리먼트가 없다면 it.hasNext() 는 false를 리턴해 while문은 종료된다, Iterator는 엘리먼트를 삭제/추가할 때도 사용 가능하다 it.remove()는 it.next()를 통해서 반환된 엘리먼트를 삭제한다.
for(int value : numbers){
System.out.println(value);
}
위 코드처럼 그냥 mumbers객체의 값을 value로 가져와 사용할 수 있다. 자바스크립트의 for in문처럼 말이다. 개인적으로 이방법이 더욱 보기에도 쉽고 편한것 같다.
전체코드
package list.arraylist.api;
import java.util.ArrayList;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
ArrayList<Integer> numbers = new ArrayList<>();
numbers.add(10);
numbers.add(20);
numbers.add(30);
numbers.add(40);
System.out.println("add(값)");
System.out.println(numbers);
numbers.add(1, 50);
System.out.println("\nadd(인덱스, 값)");
System.out.println(numbers);
numbers.remove(2);
System.out.println("\nremove(인덱스)");
System.out.println(numbers);
System.out.println("\nget(인덱스)");
System.out.println(numbers.get(2));
System.out.println("\nsize()");
System.out.println(numbers.size());
System.out.println("\nindexOf()");
System.out.println(numbers.indexOf(30));
Iterator it = numbers.iterator();
System.out.println("\niterator");
while (it.hasNext()) {
int value = (int) it.next();
if (value == 30) {
it.remove();
}
System.out.println(value);
}
System.out.println(numbers);
System.out.println("\nfor each");
for (int value : numbers) {
System.out.println(value);
}
System.out.println("\nfor");
for (int i = 0; i < numbers.size(); i++) {
System.out.println(numbers.get(i));
}
}
}
참고: 생활코딩
'BACKEND' 카테고리의 다른 글
| Mybatis 간단 사용법 익히기 (1) | 2023.11.21 |
|---|---|
| JPA 학습하기 (2편) (1) | 2023.11.20 |
| JPA 학습하기 (1편) (3) | 2023.11.19 |
| multer - 파일 업로드 관리 (Node.js) (1) | 2023.11.18 |
| MySQL 기초 (0) | 2023.11.17 |